Extract text from image to AI project
Overview
In today's digital age, extracting text from images has become a common task in various domains, from document digitization to text analysis. Optical Character Recognition (OCR) engines like Tesseract have played a significant role in making this process efficient and accessible. However, improving the accuracy and usability of OCR systems remains a challenge. In this blog post, we'll explore (based on two examples) how to enhance text extraction from images using Tesseract in conjunction with OpenAI's Generative AI capabilities.
In this blog we'll discuss some Python scripts. These scripts combines the power of Tesseract for text extraction from images and OpenAI's Generative AI to interpret and generate responses based on the extracted text. This fusion of technologies enables applications to not only recognize text but also comprehend its meaning and context.
Script Overview
The Python script begins by importing required libraries and setting up necessary configurations. It then loads an image using OpenCV and preprocesses it to enhance text visibility. The preprocessed image is then passed to Tesseract for text extraction.
Next comes the integration with OpenAI. The extracted text is used as input for generating responses using OpenAI's Generative AI model. This allows the script to understand and respond to queries or requests based on the content of the image.
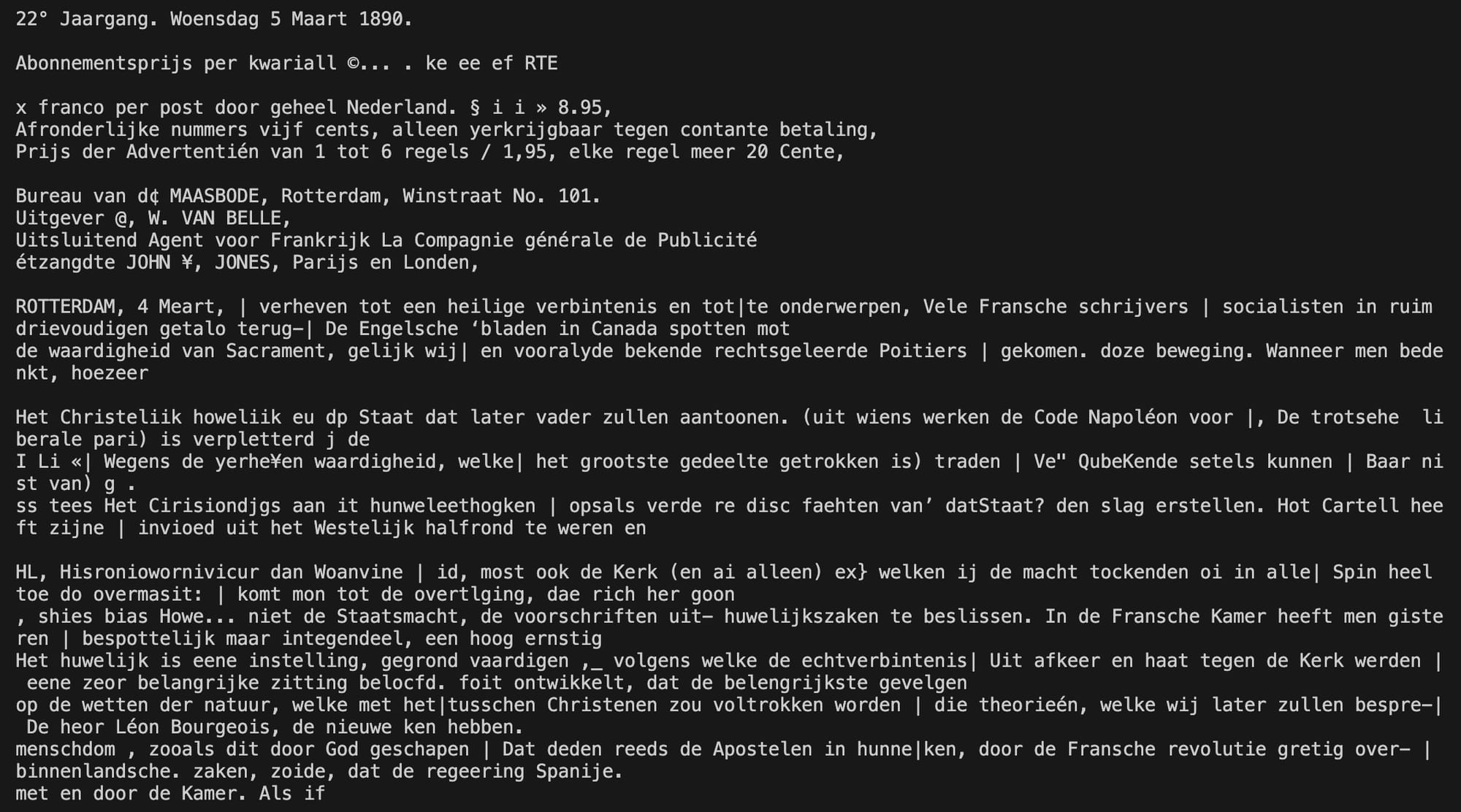
Example 1: De Maasbode
For this I used the Delpher newspapers dataset which features 2 million digitised newspapers and is maintained by the Royal Library of the Netherlands. I took an example of 'De Maasbode' newspaper originated from Rotterdam, Netherlands and dating back to 1890.

De Maasbode
Image Preprocessing
With OpenCV, the image is converted to grayscale. Furthermore image contrast and brightness are adjusted. Depending on the image this could improve the text extraction accuracy. The modified image is then written to the disk, also with OpenCV.
1# Image preparation with OpenCV
2image = cv2.imread('maasbode.jpg')
3
4# Returns image in grayscale format
5gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
6
7# Define the contrast and brightness value
8contrast = 1. # Contrast control ( 0 to 127)
9brightness = 40. # Brightness control (0-100)
10
11weighted = cv2.addWeighted(gray, contrast, gray, 0, brightness)
12
13cv2.imwrite('result.png', weighted)

Maasbode cv2 result
Tesseract OCR
The preprocessed image is fed into Tesseract for OCR. Tesseract extracts text from the image, which serves as input for further processing by OpenAI. Notice that for using Tesseract with Python the wrapper of the Tesseract OCR engine is used, called pytesseract. The image_to_string function contains a custom page segmentation method (psm), because by default number 3 is used wich means "Fully automatic page segmentation, but no OSD". I played a bit around and found out that number 4 produced better results for text extraction. Refer to the documentation for more info about page segmentation methods.
1# Tesseract with custom psm config
2custom_psm_config = r'--psm 4'
3tesseract_response = image_to_string('result.png', config=custom_psm_config)
4
5print(tesseract_response)
OpenAI with JSON mode
We can get the help of OpenAI to get a short summary about the extracted text. For this I have used the OpenAI library for Python and used the JSON mode which was released in late 2023. The response contains a JSON object with some attributes in Dutch language. In my example I didn't tell OpenAI to generate a specific JSON structure, but you can have it the way you like by providing more messages. Be aware that it doesn't guarantee a specific JSON schema.
1client = OpenAI()
2
3response = client.chat.completions.create(
4 model="gpt-3.5-turbo-1106",
5 response_format={ "type": "json_object" },
6 messages=[
7 {"role": "system", "content": "Je bent een behulpzame assistent die JSON kan genereren."},
8 {"role": "user", "content": f"Kan je een samenvatting geven van de volgende tekst? {tesseract_response}"}
9 ]
10)
11print(response.choices[0].message.content)
Response:
1{
2 "samenvatting": "De tekst uit 1890 gaat voornamelijk over huwelijksaankondigingen, wetten en aankondigingen in Nederland, Frankrijk, en diverse andere landen. Het behandelt ook politieke kwesties en gebeurtenissen uit die tijd, zoals de verandering in huwelijkswetgeving, conflicten tussen de Kerk en de Staat, en politieke ontwikkelingen in Europa en elders. Verder bevat de tekst een verhaal over nihilisten en politieke complotten.",
3 "publicatiedatum": "Woensdag 5 Maart 1890",
4 "publicatie": "MAASBODE, Rotterdam"
5}
Example 2: A view of sir Isaac Newton's philosophy
In this example I used a book A View of Sir Isaac Newton's Philosophy written by Henry Pemberton and originated from 1728.

Newtons philosophy
Image Preprocessing, text extraction and interpretation
With OpenCV, the image is converted to grayscale. The grayscale image is then converted to binary. Setting the thresold too high will result in a black image. In my example I used 180. Tesseract will OCR the text and pass this to OpenAI to give a Dutch summary.
1## Image preparation with OpenCV
2image = cv2.imread('newtonphilosophy.jpg')
3
4# Returns image in grayscale format
5gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
6
7# Convert grayscale image to binary image
8th, dst = cv2.threshold(gray,180,255,cv2.THRESH_BINARY)
9
10cv2.imwrite('result_newtonphilosophy.png', dst)

Newtons philosophy cv2 result
1# Tesseract with custom psm config
2custom_psm_config = r'--psm 4'
3tesseract_response = image_to_string('result_newtonphilosophy.png', config=custom_psm_config)
4
5# OpenAI with JSON mode
6client = OpenAI()
7
8response = client.chat.completions.create(
9 model="gpt-3.5-turbo-1106",
10 response_format={ "type": "json_object" },
11 messages=[
12 {"role": "system", "content": "Je bent een behulpzame assistent die JSON kan genereren."},
13 {"role": "user", "content": f"Kan je een samenvatting geven van de volgende tekst? {tesseract_response}"}
14 ],
15
16)
17print(response.choices[0].message.content)
OpenAI response:
1{
2 "text": "De tekst is een voorwoord waarin de auteur uitlegt dat hij werd aangemoedigd door vrienden om zijn werk over Isaac Newton's Principia openbaar te maken. Hij hoopt dat zijn werk de filosofie van Newton begrijpelijk maakt voor niet-wiskundigen en jonge wetenschappelijke geesten aanmoedigt om zich meer bezig te houden met de wiskundige wetenschappen. Hij heeft de tekst geschreven met de intentie om de ideeën van Newton toegankelijker te maken voor een breder publiek."
3}